


Welcome! This is the first post detailing what I hope will be a fun and interesting long-term project. My vision is to build a modern version of the Memex, imagined up by Vannevar Bush in 1945, but which sadly never saw the light of day.
The intention was to create a system that allows its user to sort and search through the massive amounts of data in one’s research library. In today’s world, our “research library” can be thought of as the boatload of data we have strewn across different services and apps, with no easy way of unifying everything.
But Why?
As I continue to build mine, I hope to share the process (and the code) of building this so that those who are so inclined can better think about creating their own. Over the months I’ve spent tinkering on this, I’ve realized just how difficult of an undertaking it is — it’s difficult to automate, a lot of data is inaccessible, and it just feels I’m not supposed to be doing this. Regardless, I’m having a blast with this so I’m going to continue building and sharing.
This first post was inspired by a talk given by Simon Willison, on the notion of Personal Data Warehouses in which he shows the value of porting all of your data across various services into local databases (he has written a bunch of importers that transform this data into SQLite tables).
To create my own data warehouse, I needed to figure out exactly what sources of data I want to collect and more importantly WHY I want to collect them. This informs how I structure the database, architect the systems, and the fundamental direction of the project itself.
When I first began, I wanted to create a personal search engine, inspired by Linus Lee’s Monocle. The goal at the time was to index ALL of my personal data, and be able to search over it efficiently. Eventually, I realized this wasn’t too valuable for me (full-text search on its own isn’t quite useful) and once Rewind launched, it was game over since I now have near perfect memory over everything that I’ve done on my computer.
There are still, however, four major problems that aren’t solved yet, and those are what I plan to tackle over the course of this project.
Lifelog: I want to see everything that I’ve done (texts sent, websites visited, pictures taken) in the same interface with context (my location, heart rate, how well I slept that night, etc.) to better inform what was actually going on. Google Timeline kind of does this, but only includes a tiny sliver of my data.
Semantic Search: Rewind lets me search for anything that I’ve seen while browsing the internet, but seems to be pretty rigid in its search criteria. Not to mention, it doesn’t work have access to 10+ years of historical data. Implementing semantic search will involve creating a separate infrastructure to index searchable text data into language embeddings so that eventually I’ll be able to search for concepts and vibes rather than exact words.1
Actionable Insights: Okay I have all this data, but so what? The magic comes in when I'm able to use this data to encourage positive behaviors, gain insight into myself2, or even automate certain parts of my life. I'm talking dashboards, weekly summaries, automated habit trackers, and more!
NikhilBot: This one’s a bit of a stretch, but I don’t think it’s impossible to imagine what I could eventually do with all of this data in an easily accessible and organized format (which is continually and automatically updating over time). I could fine-tune a large language model that will know everything about Historical Nikhil and help Present Nikhil become the ideal version of Future Nikhil. 🚀
Infrastructure
As a fun challenge to myself, I’m trying to keep this project as lightweight as possible in terms of expenses & footprint. I already pay $6 a month for a DigitalOcean droplet which is just a tiny cloud server to host all of my personal projects, so I’m going to shoehorn all of the services, data, and infrastructure for my Memex into this machine and really take efficiency to its limits.
There’s a certain magic and self-sufficiency3 to this approach, which matches the energy of creating my own Memex in the first place. It feels like I’m taking ownership of my data and doing it in a way that’s cheaper than my Netflix subscription. Since I’m literally the only person who will ever access this data, there are a lot of things I can simplify, and the only question of scale is that of the size of my data.
The services that I plan to build and put on this server include…
PostgreSQLdatabase to hold all of my dataRead / Write endpoints to the database via a lightweight
FlaskAPIPinecone (vector database) to hold embeddings for semantic search
The frontend written in
Next.jsand hosted via anNginxreverse proxyCron jobs for the
Pythonscripts that will do auto-import dataTelegram bot written in
Node, which will ping me at regular intervals to collect manual dataMisc. services for handling analytics, alerting, dashboards, automated insights, and whatever else this project evolves into
Data, Data, Data
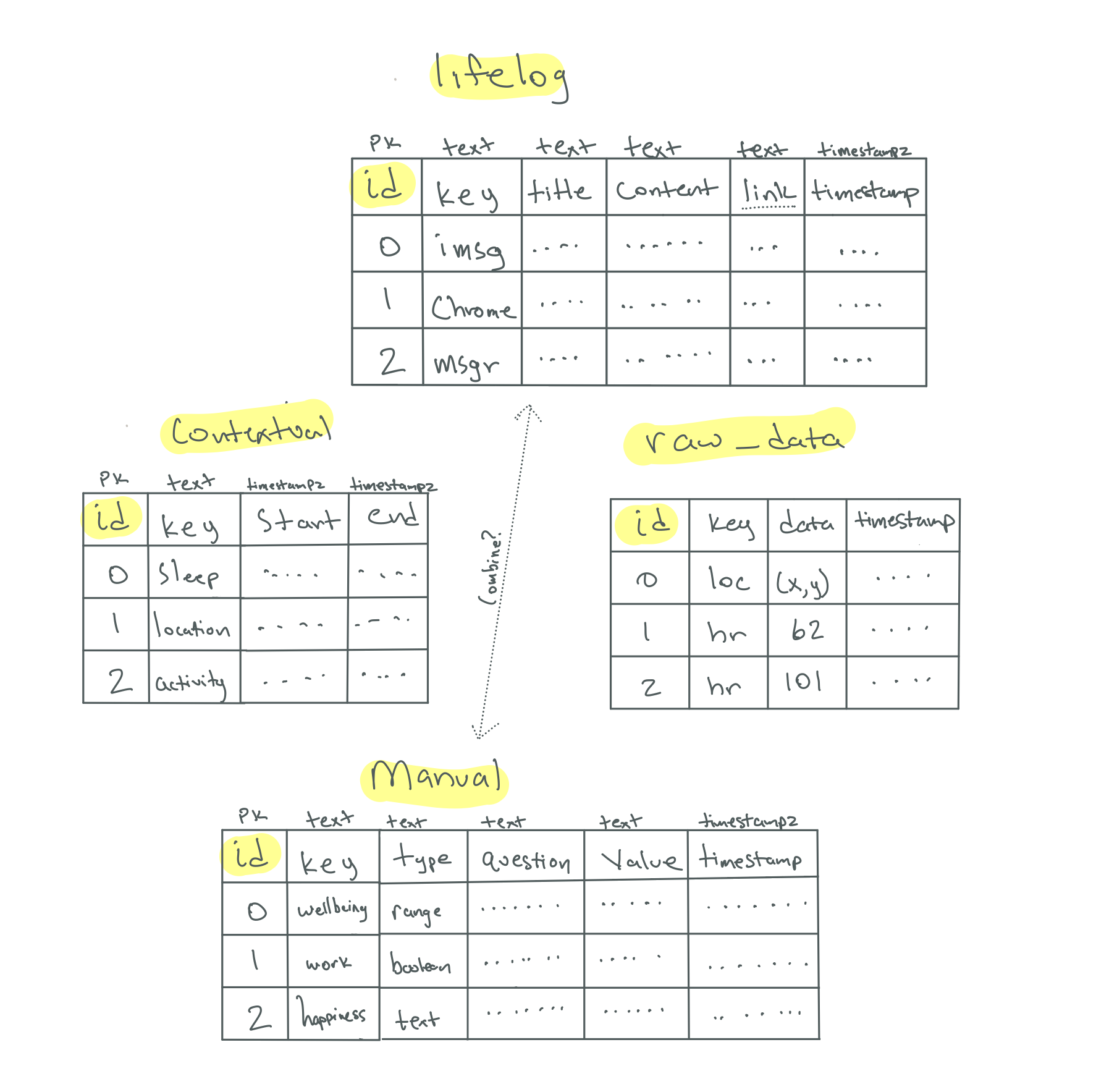
Here’s how I’m structuring my data for now. I was looking for a schema that’s not too complicated but is general enough to let me add more sources of data in the future, however they may be structured
lifelog
this is a way to see exactly what I did at or around any given time using timestamps
FB Messenger
iMessage / Texts
YouTube watch history
Chrome browsing history
Spotify listening history
Roam Research notes
Historical journal (Sheets & Notion)
Tweets
contextual
useful data overlays passively collected to better inform what I did within a range of time
Location
Activity (walking, on a bus, etc.)
Sleep
Calendar blocks
raw_data
for more demanding analytics / overlays
Heart rate
Individual latitude / longitude points
manual
anything entered manually for tracking — could possibly be merged with lifelog in the future
Subjective feelings throughout the day (1-10 score)
Weekly assessments (1-10 score) of different areas of life
Qualitative answers to relevant questions
By collecting and organizing my personal data in this way, it allows my Memex to be more than just a search engine, lifelog, or whatever else I use it for. It’s a platform that leverages this data warehouse to do pretty much anything I want with it in the future.
That’s enough writing for now — it’s time to keep building. Currently I’m working on the read/write API that sits in front of my database, as well as some higher-level architectural designs. In addition, I’m trying to build the right habits and systems (via the Telegram bot) to semi-passively collect manual data (e.g. subjective wellbeing & questions to myself).
Next post might cover how to download / extract (and automate) all of the sources of data listed, the behavioral process of building manual data collection habits, or something else entirely. Stay tuned. ✌🏽
For now, I kind of get full-text search for free since I can take advantage of the magical %like% operation found in SQL.
Felix Krause is my north star for this. He’s been tracking a LOT of things for years and has some fascinating analyses of his personal data.
Please ignore the fact that I am using a cloud service, I could host my own Ubuntu box but IMO the headaches and logistical issues that get eliminated from using a cloud server is well worth it. Plus, I could very easily migrate it all to a local machine in the future if I want to.